

Have you ever thought why LLMs (large language models) give vague and generalized answers and still they feel confident? This is because they are trained on large data sets. To give specific answers with indepth information for a particular question, they need information from an external source. Retrieval Augmented Generation (RAG) helps these models to get information from up-to-date and domain specific information.
We will explain what RAG is, how it works, and what are its benefits.
What is RAG?
RAG is a technique that can enhance the performance of generative AI models by connecting them with external sources. It helps LLMs to give relevant and specific information. All gen AI models are trained on vast datasets so they generate generalized outputs. It connects the search engines with generative models. This ensures that gen AI models do not rely solely on already trained data rather they can retrieve information from external sources.
Why is it Important to Use RAG?
LLMs are trained on a vast amount of data which becomes outdated after a certain time period. These are like employees who refuse to update information with time but remain very confident in answering questions. This results in issues like hallucination, and generic answers.
Lack of Specific Information
Due to the vast amount of data used in training LLMs, they give vague and generalized answers. If you ask for information about troubleshooting in your particular software they will not give you a specific answer. This is because they are not trained on data specific to your software.
Hallucinations
Hallucination means that AI models can give answers based on incorrect facts. When gen AI models do not know something, they fabricate answers.
RAG helps to give domain specific answers by connecting LLMs with external sources like your company documents or data.
Core Components of RAG
There are four main components of RAG:
- Knowledge Base: This is the external repository of data where all factual information is stored.
- Retriever: It is an AI model which scans the knowledge base and fetches relevant and up-to-date information.
- Integration Layer: It connects the generator and retriever by managing inputs and outputs.
- Generator: It is LLM which generates the output based on user query.
How RAG Works?
These are few steps that RAG follows:
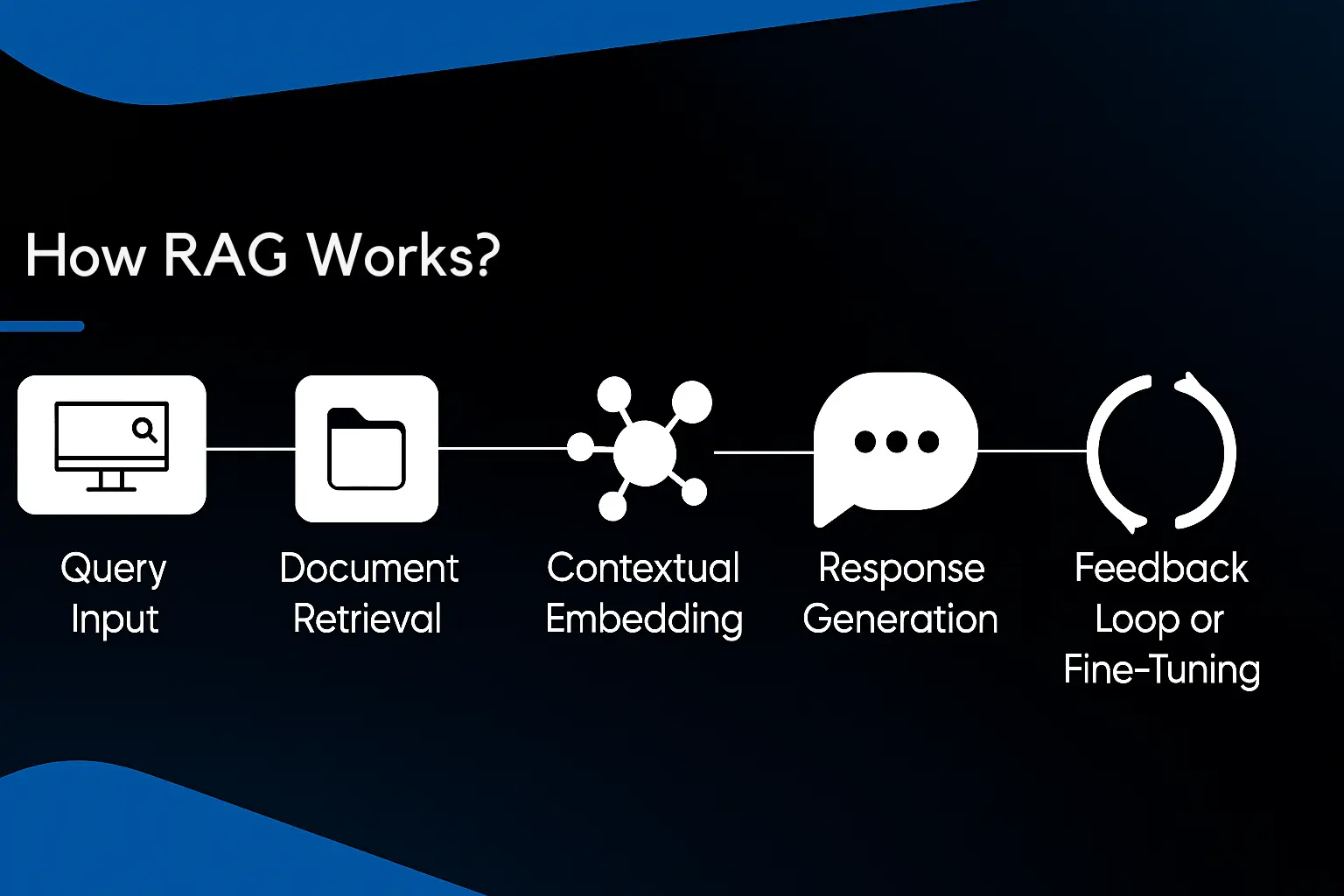
Query Input
First, the user sends a query to the LLM. This query is sent to the retriever to fetch information relevant to the query.
Document Retrieval
The retriever searches the knowledge base to find relevant information. It uses semantic embedding to find content that matches with the prompt submitted by the user. It selects the top content from the knowledge base to ensure factual correctness of information.
Contextual Embedding
When documents are selected by the retriever, they are transformed into contextual embeddings. It is a process to ensure that content is relevant. Furthermore, the original query is combined with contextual embeddings to form a comprehensive input for the generator.
Response Generation
The refined query is given to a generator which generates content based on facts. Due to RAG, LLMs generate content that is based on real facts and up to date information. It improves the trust of users and reduces chances of hallucination.
Feedback Loop or Fine-Tuning
In some cases, especially when RAG is operating on an enterprise scale, it has a feedback loop. It depends on user experience and feedback to update its information. Developers also fine tune the generator by domain specific information.
Benefits of RAG
These are several benefits of RAG:
- It reduces the cost of frequent retraining of LLMs.
- It reduces the chances of hallucination.
- It allows LLMs to give current and most relevant information.
- Factually correct answers enhance the user’s trust.
- It allows more control over the knowledge source of gen AI models.
RAG Use Cases
RAG systems are applied across many domains:
Specialized chatbots and virtual assistants
Enterprises who want to automate customer support may face challenges because AI chatbots lack updated information about the company and product. RAG systems can give current information to chatbots by accessing the company's data. Similarly, RAG systems can help virtual assistants to give personalized information. They link the personal assistants to the user's previous data to understand the user’s query in a better way.
Market analysis
RAG also helps the business leaders to consult current news and social media trends that helps in better informed decisions. Product managers can also use it to understand user behaviour and preferences. This will help them to develop products according to user choice.
Research
RAG systems are able to consult external sources and read documents. This makes them an excellent source of research. For example, financial analysts can use RAG to write company reports based on up-to-date information.
What is the Semantic Search Layer of RAG?
The semantic search layer of RAG consists of two components; embedding model and vector base.
Embedding Model
It works to convert the text into code. It represents the original query into numerical representation while keeping the semantic meaning of the original text. For example, OpenAI's text-embedding-ada-002 works as an embedding model.
Vector Stores
A vector store or database is a specialized store that stores the embeddings. When you insert any document in LLMs, it is converted into embedding or vector. Vector stores save these vectors for efficient retrieval. For example, Facebook’s FAISS and Chroma DB are open source vector stores.
Challenges in Implementing RAG Systems
Despite many advantages, there are few challenges in implementing RAG systems. Let’s explore these issues:

Data Quality
The quality of the knowledge base determines the success of RAG. If the documents in the knowledge base are outdated then it will result in incorrect answers.
Retrieval Mechanism
The optimized vector store and retriever are essential for any RAG system. If the retriever is poor in fetching information, it will result in incomplete answers.
Embedding Quality
If data is not embedded well then retriever will be less efficient in retrieving information. A wrong embedding model can result in less contextual information.
Chunking of Documents
RAG systems do not work on entire documents. It works on document chunks. If document chunks are too large then it will be difficult to retrieve information. Additionally, if document chunks are too small then retrieval will be inefficient.
Best Practices to Avoid RAG Implementation Challenges
These are the best practices that you need to follow while implementing RAG:
- Ensure up-to-date knowledge base
- Avoid too small or too large chunks
- Embedding models must be domain specific
- Use scalable vector bases.
Conclusion
Retrieval Augmented Generation (RAG) has become the need of the hour. Companies using gen AI models need RAG to give personalized and up-to-date information. Without RAG, LLMs give incorrect and outdated answers. It reduces the chances of hallucination, generic answers, and vague outputs.















